
Running an always-on autonomous agent system using Microsoft Foundry with the Microsoft Agent Framework works extremely well. The orchestration model is solid, and the developer experience is strong.
However, as event volume increases, another constraint emerges: LLM quota and rate limits (TPM/RPM).
Consider a fleet of 50 trucks sending telemetry every five seconds. That produces 600 events per minute. In a four-agent workflow where each step invokes an LLM, this expands to 2,400 LLM calls per minute, before accounting for token volume per call. Even with a well-designed architecture, that volume can quickly approach model throughput limits. The symptoms are familiar: HTTP 429 rate-limit responses, retry backoff, compounding latency, and unpredictable system behavior under load.
The challenge isn’t Foundry or the Agent Framework. It’s treating LLM reasoning as a uniform step for every event in a high-frequency stream. In most telemetry systems, the majority of events are routine heartbeats, signals that everything is operating normally. LLM inference is a premium, quota-bound resource, and applying it indiscriminately to uneventful data is both expensive and unnecessary.
The solution was to introduce a deterministic pre-filter: a lightweight function that evaluates structured telemetry and determines whether an event warrants agent reasoning, without invoking an LLM. This reduced request volume by approximately 95%, immediately relieving quota pressure and stabilizing throughput.
An additional benefit followed. With a predictable and scoped workload, it became practical to right-size the model from gpt-4.1 to gpt-4.1-mini. That change delivered meaningful cost savings while maintaining solution quality.
This post explores both optimizations, the data behind them, and the architectural trade-offs to consider when building high-frequency agent systems.
The System: FleetMind
FleetMind is an autonomous operations platform for long-haul trucking. Built with Microsoft Foundry and the Microsoft Agent Framework, it monitors fleets ranging from 50 to 200 trucks operating across the U.S. Midwest corridor.
The platform processes a continuous telemetry stream from each vehicle, including GPS position, speed, fuel level, engine diagnostics, driver hours of service (HOS), and cargo temperature.
The architecture is fully event driven. Every truck publishes telemetry to Azure Service Bus every five seconds. Events are consumed by services running in Azure Container Apps, where specialist agents evaluate conditions and take autonomous action: rerouting for weather and traffic, scheduling preventative maintenance, flagging HOS violations, or escalating critical alerts.
All decisions are logged to Azure Cosmos DB for audit traceability. Tool invocations—such as maintenance lookups, compliance checks, and route evaluations—are exposed through Azure API Management (APIM) using the Model Context Protocol (MCP).
For background on building always-on autonomous agent systems, see From Chatbots to Autonomous Agents: Building an Always-On Risk Platform—a similar implementation is deployed on AKS in a financial risk context. FleetMind applies similar core principles, but at significantly higher event frequency. It is at this scale that LLM quota and throttling considerations become architectural factors rather than operational edge cases.
Four specialist agents handle the domain logic:
| Agent | Responsibility |
|---|---|
| Maintenance Agent | Engine health, fault diagnostics, fuel thresholds |
| Compliance Agent | HOS violations, speed limits, hazmat/refrigerated cargo |
| Route Optimizer | Weather/Traffic rerouting, ETA variance, delayed status |
| Alert Agent | Critical escalations for safety threshold breaches |
The Problem
At 50 trucks sending an event every five seconds, the system receives 600 events per minute, or 36,000 per hour.
Under a pure multi-agent pattern, each event is evaluated by four specialist agents. Each agent invokes the LLM to reason over the telemetry and determine whether action is required.
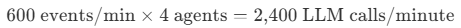
At standard quota allocations, this volume quickly approached Microsoft Foundry rate limits. The system began returning HTTP 429 rate limit responses. Retries increased latency. Concurrent MCP tool calls, with each agent establishing its own session through APIM, further amplified downstream load.
The architecture itself was sound. The issue was applying LLM reasoning uniformly across every event in a high frequency stream, most of which were routine heartbeats that required no action.
Microsoft Foundry provides mechanisms to scale, including additional quota allocation and provisioned throughput. Those controls are intended to extend an efficient design, not replace one.
The real fix was architectural: stop invoking the LLM when no reasoning was required.
Two Architectural Patterns
Before getting into the solution, it helps to clearly define the two approaches and when each is appropriate.
Pure Multi-Agent Orchestration
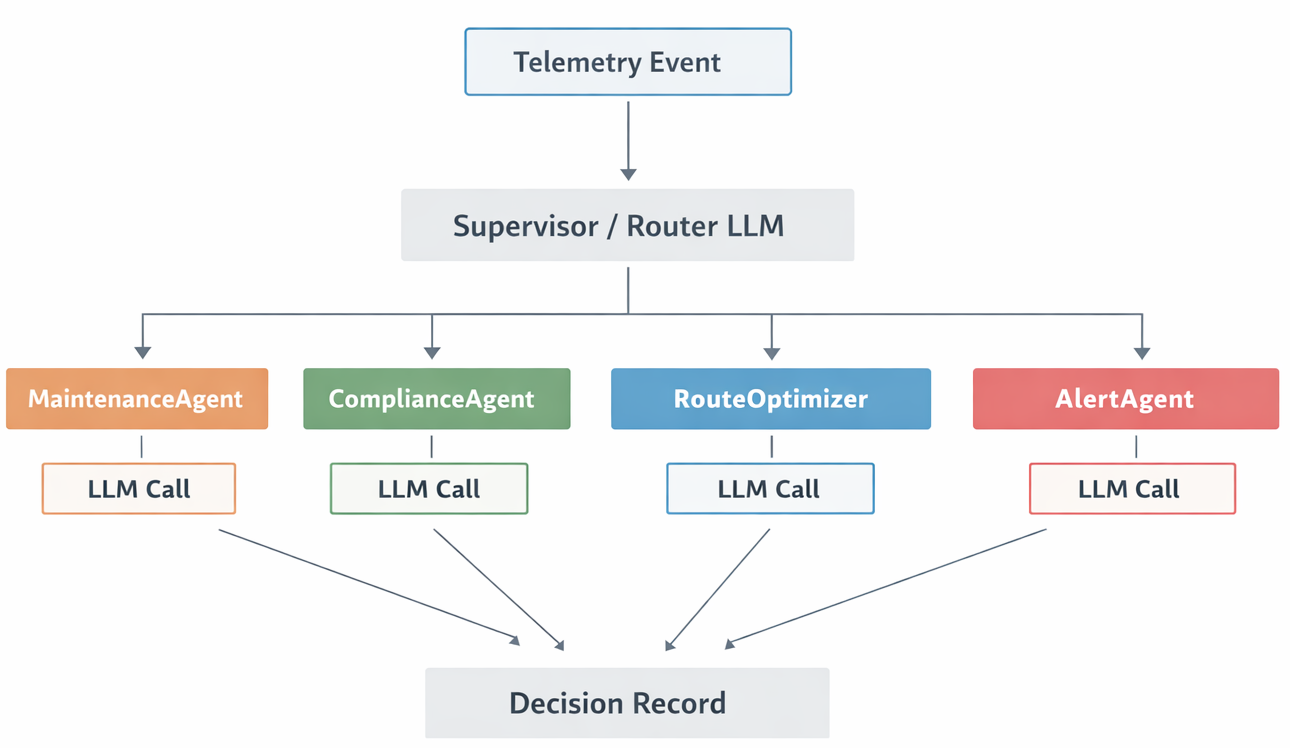
A supervisor or routing agent receives the event, uses an LLM to determine which specialist agents to invoke, and then coordinates execution. In this pattern, every event incurs at least one LLM call before any work begins. Even in its simplest form, this introduces an additional orchestration agent and a fixed reasoning cost per message.
This pattern maximizes flexibility. The model can reason over structured or unstructured input, handle novel conditions, and adapt without code changes.
It is appropriate when event volume is low enough to keep LLM call rates comfortably within quota and budget, when inputs are unstructured or unpredictable, when business logic changes frequently enough that prompt updates are faster than redeployment, or when every decision justifies full LLM reasoning regardless of cost.
Deterministic + Agent Hybrid
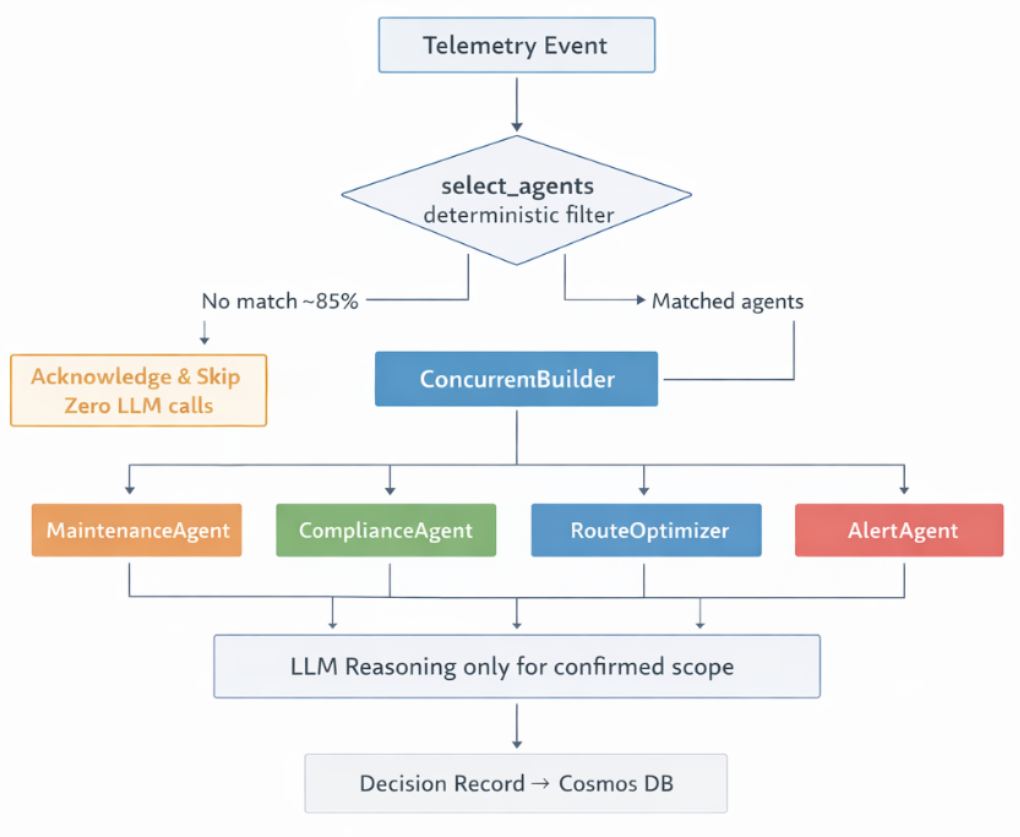
Structured event fields drive agent selection through code. No LLM is involved in routing. Only agents matched by triage rules are invoked. Events with no matching conditions are acknowledged and skipped entirely.
LLM reasoning is reserved for confirmed, in scope decisions.
This pattern is appropriate when event volume would otherwise push LLM consumption beyond quota or budget, when inputs are well structured and easily expressed as rules, when the operational domain is stable and well understood, and when predictable, bounded LLM usage is required.
FleetMind sits firmly in the second category.
Its telemetry fields are typed and bounded: engine_health is a float between 0.0 and 1.0, driver_hours represents hours remaining, and fault_codes is a list. These values are not ambiguous. Determining whether one is missing or out of range does not require a reasoning model. It requires a comparison.
The Deterministic Triage Layer
The core change was introducing select_agents(), a pre-filter that reads structured event fields and returns the list of agents relevant to that specific event. No LLM is called. No tokens are consumed. It’s just code.
# Triage thresholds — edit here, not scattered across agent prompts
ENGINE_HEALTH_WARN = 0.70 # below → maintenance
ENGINE_HEALTH_CRIT = 0.35 # below → also reroute + alert
FUEL_LOW_FRACTION = 0.15 # below → maintenance
HOS_WARN_HOURS = 2.0 # below → compliance
HOS_CRIT_HOURS = 1.0 # below → also alert
SPEED_LIMIT_MPH = 65.0 # above → compliance
ETA_LATE_MINUTES = 30.0 # above → routing
def select_agents(event: TelemetryEvent, agents: dict) -> list:
selected = []
needs_alert = False
# Maintenance
if (
event.engine_health < ENGINE_HEALTH_WARN
or event.fault_codes
or event.maintenance_needed
or event.fuel_level < FUEL_LOW_FRACTION
):
selected.append(agents["maintenance"])
if event.engine_health < ENGINE_HEALTH_CRIT or event.fault_codes:
needs_alert = True
# Compliance
if (
event.driver_hours < HOS_WARN_HOURS
or event.speed > SPEED_LIMIT_MPH
or event.cargo_type in ("hazmat", "refrigerated")
or any("E0003" in fc for fc in event.fault_codes)
):
selected.append(agents["compliance"])
if event.driver_hours < HOS_CRIT_HOURS:
needs_alert = True
# Routing
if (
event.active_weather_event
or event.eta_variance_minutes > ETA_LATE_MINUTES
or event.engine_health < ENGINE_HEALTH_CRIT
or event.status == "delayed"
):
selected.append(agents["route_optimizer"])
# Alert (only when a hard threshold is breached — not just "at_risk" status)
if needs_alert:
selected.append(agents["alert"])
return selected
If select_agents() returns an empty list, the event is acknowledged and the workflow exits. Zero LLM calls. For a routine heartbeat (engine healthy, driver rested, no faults, no weather), that’s exactly what happens.
When agents are matched, only the matched subset runs via ConcurrentBuilder. A non-critical event that only triggers ComplianceAgent (say, a refrigerated cargo truck requiring manifest validation) uses 1 LLM call instead of 4 (or 5 with the supervisor). That selective execution compounds the savings.
Triage Rule Summary
| Agent | Triggered when |
|---|---|
| MaintenanceAgent | engine_health < 0.70, any fault codes, scheduled maintenance due, or fuel < 15% |
| ComplianceAgent | driver_hours < 2h, speed > 65 mph, hazmat/refrigerated cargo, or HOS fault code |
| RouteOptimizer | Weather/Traffic alert active, eta_variance > 30 min, engine_health < 0.35, or status is “delayed” |
| AlertAgent | engine_health < 0.35, critical fault codes, or driver_hours < 1h |
In simulation, approximately 85% of events match zero triage rules. Those are routine heartbeats (position updates from trucks running normally). In a pure multi-agent approach, each of those events would still invoke 4 LLM calls (or at minimum the router agent), consuming roughly 500 tokens per agent × 4 = 2,000 tokens per event, for events that require no action at all.
What the Measurements Showed
With deterministic triage in place, I reviewed the Microsoft Foundry request metrics dashboard.
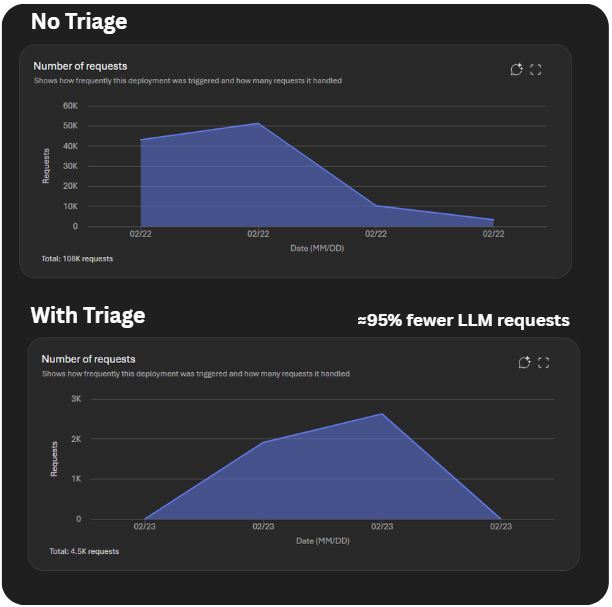
Request volume dropped from approximately 100,000 calls to about 4,500 calls, representing a ~95 percent reduction in LLM invocations.
The theoretical expectation was closer to a 90 percent reduction. The measured result was slightly higher, likely because the real-world event distribution contained an even larger proportion of routine heartbeat telemetry than the 85 percent simulation estimate predicted.
Token volume per call did not change materially. The remaining 4,500 requests represented genuine operational decisions: confirmed fault conditions, driver hours of service alerts, and weather routing actions. These calls carried meaningful context and produced actionable output. Hourly token consumption remained roughly 47M tokens.
The eliminated calls were noise. The remaining calls were the actual workload.
The operational effects were immediate.
HTTP 429 rate limit errors dropped to near zero. Concurrent MCP tool calls were reduced from as many as four agent invocations per event to typically one or two matched specialist agents. This reduced API Management load and eliminated the session ID race conditions that had previously caused intermittent HTTP 400 errors.
Throttle Control: Three Layers
Triage was the primary lever, but not the only control mechanism. Managing HTTP 429 responses in a high frequency event loop required a layered design.
Layer 1 — Deterministic Triage
The system eliminates unnecessary LLM calls for roughly 85 percent of events before any network request is made. This behavior was described earlier.
Layer 2 — Sequential Message Dispatch
The Service Bus receiver processes messages sequentially rather than using batch parallel dispatch.
Sequential processing bounds concurrent MCP sessions to a single event flow. Each event typically results in approximately five to nine tool sessions, depending on which agents are invoked.
# Sequential — not asyncio.gather — to bound concurrent MCP sessions
for msg in messages:
lock_renewer.register(receiver, msg, max_lock_renewal_duration=300)
await _handle_message(msg, receiver, orchestrator, semaphore, cfg)
Using batch parallel constructs such as asyncio.gather would multiply session load by batch size. For example, if ten messages arrived simultaneously, the system could attempt fifty to ninety concurrent MCP tool sessions against APIM. The stateful MCP gateway can return HTTP 400 errors when too many sessions race on the same API instance. Sequential dispatch eliminates this contention class entirely.
Layer 3 — Semaphore + Exponential Backoff
A global semaphore enforces a ceiling on concurrent LLM coroutine execution regardless of batch arrival patterns. Throttle responses that do propagate trigger retry logic using exponential backoff with jitter.
Each retry attempt increases the delay interval up to a configured maximum bound.
# Global concurrency ceiling — set in config
semaphore = asyncio.Semaphore(cfg.max_concurrent_llm_calls)
async def _handle_message(message, receiver, orchestrator, semaphore, cfg):
...
attempt = 0
delay = cfg.llm_retry_base_delay_seconds
async with semaphore:
while True:
attempt += 1
try:
await orchestrator.run(event.model_dump_json())
await receiver.complete_message(message)
return
except Exception as exc:
if _is_throttle_error(exc) and attempt < cfg.llm_retry_max_attempts:
jitter = random.uniform(0, delay * 0.2)
wait = min(delay + jitter, cfg.llm_retry_max_delay_seconds)
await asyncio.sleep(wait)
delay = min(delay * 2, cfg.llm_retry_max_delay_seconds)
else:
await receiver.abandon_message(message)
return
The three layers address distinct failure modes:
• Triage reduces request volume
• Sequential dispatch prevents MCP session collisions
• The semaphore provides protection against quota exhaustion
No single change solved the reliability problem. The system required all three mechanisms working together.
Win 2: Model Right-Sizing
With deterministic triage in place, the LLM workload became predictable. Only well scoped, confirmed decisions reached the model. Inputs were structured, contexts were bounded, and tasks were defined clearly enough to provide high confidence in model behavior.
That predictability made it practical to move from gpt-4.1 to gpt-4.1-mini.
The dominant cost reduction did not come from the 95 percent call reduction. It came from model right sizing.
| Model | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| gpt-4.1 | $2.00 | $8.00 |
| gpt-4.1-mini | $0.40 | $1.60 |
| Reduction | 80% | 80% |
Token volume stayed at approximately 47M tokens/hour. Applying input/output split (~33M input, ~14M output):
| Model | Hourly cost |
|---|---|
| gpt-4.1 | 33 × $2.00 + 14 × $8.00 = ~$178/hour |
| gpt-4.1-mini | 33 × $0.40 + 14 × $1.60 = ~$35.60/hour |
| Saving | ~80% per hour |
For a system running continuously, the hourly difference compounds into substantial operational cost reduction.
The critical insight is that deterministic triage did not solely reduce cost by eliminating tokens. It reduced cost by making a smaller, less expensive model operationally safe to use.
When every call represents a confirmed decision on a well scoped problem, there is much higher confidence that a smaller model will perform reliably. The triage layer created the workload predictability that enabled model right sizing.
Trade-offs: What This Approach Gives Up
This approach introduces meaningful trade-offs. It is important to be explicit about what is sacrificed in exchange for throughput, predictability, and cost control.
What Is Lost
Edge case blind spots. Hard thresholds can miss novel risk combinations. Consider a truck reporting engine_health = 0.72 combined with three hours of sustained elevated temperature in a remote region. Each metric is individually acceptable, and no triage rule fires. A reasoning model might recognize the compounded pattern. Deterministic filtering generally will not.
Soft signal reasoning. Borderline readings that do not individually violate thresholds but collectively suggest emerging risk are difficult to capture with rule-based logic. The filter only evaluates defined conditions.
Rule maintenance burden. As the operational domain evolves, new vehicle classes, updated regulatory requirements, or additional cargo categories, triage rules must be updated in code and redeployed rather than simply re-prompted. Pure agentic systems shift more of this burden to runtime reasoning.
Unstructured or novel inputs. If telemetry includes free text driver observations, images, or sensor anomalies that do not map to typed fields, deterministic filtering cannot evaluate them. The approach requires structured input domains.
When Pure Agentic Is the Right Choice
| Scenario | Why pure agentic wins |
|---|---|
| Low event volume | Full LLM-per-event cost is manageable; the complexity of triage isn’t justified |
| Highly unstructured inputs | Natural language, documents, images: rules can’t evaluate these |
| Novel or unpredictable conditions | When conditions can’t be enumerated at design time |
| High-stakes, low-frequency decisions | Contract review, legal triage, medical; each decision justifies full LLM reasoning |
| Rapidly changing business logic | When conditions change faster than a code deployment cycle |
The design principle that emerged from this work is straightforward.
Use deterministic logic for detection. Use LLMs for remediation.
In FleetMind, telemetry fields are typed, bounded, and rule expressible. The primary value of the LLM is reasoning about remediation once a problem has been confirmed, not determining whether a numeric field crosses a threshold.
Platform Notes: Microsoft Agent Framework and Microsoft Foundry
The implementation relies on two platform components worth highlighting.
Microsoft Agent Framework provides the workflow primitives used throughout the system. ConcurrentBuilder enables parallel execution across matched agents. SequentialBuilder supports ordered workflows within an agent. MCPStreamableHTTPTool handles MCP tool integration. The framework manages agent lifecycle, tool invocation, and context passing.
FleetMind’s triage logic sits upstream of the framework, not inside it. Deterministic prefiltering and the Agent Framework are complementary. The framework orchestrates reasoning. Triage determines when reasoning is necessary.
Microsoft Foundry provides the inference layer, model management, quota controls, and observability that made the impact measurable. The Foundry dashboard clearly showed the request volume drop from roughly 100K to 4.8K. Without that visibility, the value of triage would have been much harder to quantify.
The model swap from gpt-4.1 to gpt-4.1-mini was simply a configuration change in Foundry. No agent code required modification.
What I Would Do Differently
One area I initially underestimated was the importance of defining triage thresholds carefully from the outset.
Constants such as ENGINE_HEALTH_WARN and HOS_WARN_HOURS encode domain knowledge. Once embedded in code, changing them requires deployment. I initially treated them as provisional and refined them iteratively.
In a production system with live operational data, I would instrument the triage layer itself. That means tracking what percentage of events each rule captures, identifying overlap between rules, and validating that thresholds align with the actual telemetry distribution.
The effectiveness of deterministic triage depends entirely on rule precision. If thresholds are too broad, LLM reduction shrinks. If they are too narrow, important signals may be missed. Calibration is continuous work, not a one time task.
Conclusion
Running a multi-agent system at this scale without triage is a quota-saturation problem waiting to happen.
The question is not whether to use agents. It is which events truly require reasoning.
The change that made FleetMind operationally viable was simple: evaluate structured telemetry in code, skip events that do not require reasoning, and invoke only the agents warranted by the event. The 95 percent reduction in LLM calls was not an optimization. At this frequency, it was a requirement.
The second order effect was the real cost lever. Moving from gpt-4.1 to gpt-4.1-mini became possible because workload volume was predictable. The savings came not from fewer tokens alone, but from running a right sized model made viable by deterministic triage.
This is not a universal pattern. It is a targeted one. If your system processes structured, high frequency events at a rate where indiscriminate agent invocation would saturate quota within minutes, this approach is worth evaluating.
In FleetMind, LLM reasoning was truly necessary for about 5 percent of events.

Leave a Reply