
In modern cloud operations, the gap between a critical alert firing and an engineer identifying the root cause is often filled with manual log-spelunking. We pivot between logs, metrics, and source code, trying to reconstruct the state of the world at the moment of failure. While observability has improved, the response itself remains largely reactive.
The next evolution is Agentic Reliability. By leveraging the Azure SRE Agent, we can move beyond passive monitoring to build Self-Healing Pipelines. These are systems that don’t just flag problems; they autonomously investigate, reason over the incident context, and stage the fix.
Why Now? The Inflection Point of Agentic SRE
We’ve had “automated” monitoring for a decade, but agentic SRE is only becoming a reality now. This is driven by two technical shifts:
- Context Window Expansion: Analyzing a production failure requires the “full picture.” Today’s models support context windows large enough to ingest entire Kusto log streams, multi-file stack traces, and relevant source code simultaneously without losing the “needle in the haystack.”
- Standardized Tooling (MCP): The Model Context Protocol (MCP) has standardized how agents interact with the world. Instead of brittle, custom integration scripts, the Azure SRE Agent natively “talks” to Log Analytics, Azure Resource Graph, and GitHub through a unified interface.
The Architecture: The Self-Healing Reasoning Loop
A self-healing pipeline creates a closed-loop system where detection leads to autonomous investigation. Rather than waiting for a human to start the triage, the agent is triggered by the incident itself.
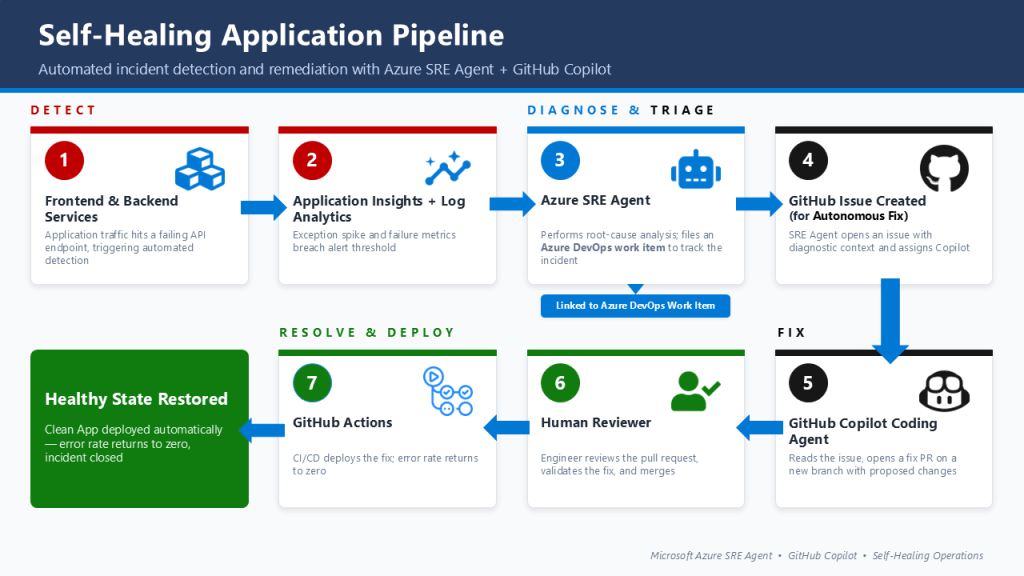
The core of this workflow revolves around a structured Reasoning Loop:
- Detection: An incident is identified via Azure Monitor, Application Insights
- Autonomous Investigation: The agent retrieves “Deep Context”, correlating telemetry from Log Analytics with recent changes in the GitHub repository.
- Root Cause Analysis (RCA): The agent identifies if the issue is a code regression, configuration drift, or resource failure.
- Governed Remediation: The agent hands off findings to GitHub Copilot to generate a fix and open a Pull Request.
The Handoff: Achieving Governed Autonomy
The term “Self-Healing” often makes architects nervous, and for good reason. A rogue agent with “Write” access to production can turn a minor blip into a catastrophe. To solve this, my implementation focuses on Autonomous Investigation but Governed Remediation.
We achieve this by structuring the workflow across a clear Autonomy Spectrum:
| Capability | Mode | Action |
|---|---|---|
| Data Gathering | Autonomous | Querying Log Analytics and Kusto without human intervention. |
| Root Cause Analysis | Autonomous | Correlating telemetry with commits to find the “breaking change.” |
| Code Remediation | Governed | GitHub Copilot generates a Pull Request based on the agent’s findings. |
| Production Apply | Manual | The Human Gate: An engineer reviews the PR and hits “Merge.” |
By using the GitHub Pull Request as the ultimate safety gate, we stay within existing CI/CD governance. We aren’t removing the human from the loop; we are removing the toil from the loop. In this ecosystem, the Azure SRE Agent provides the intelligence, GitHub Copilot handles the implementation, and the human remains the final authority.
Reference Implementation: The Demo Repository
To demonstrate these patterns in a production-oriented context, I’ve released a reference implementation that connects these pieces together.
GitHub Repository: jonathanscholtes/azure-sre-agent-github-demo
The repository provides a blueprint for:
- FastAPI Backend: A Container App target for monitoring and remediation.
- Synthetic Load Generator: A Container App Job that triggers failures to test the agentic loop.
- Deployment Automation: A unified PowerShell script to set up Managed Identities, OIDC for GitHub, and the necessary Azure AI resources.
Lab: Inducing a Failure (Chaos Engineering)
To validate the pipeline, the implementation includes a “Walkthrough” designed to inject repeatable failures. We use the Start-SreDemo.ps1 script to introduce semantic bugs like KeyError (renaming variables in calculation logic) or AttributeError (breaking request parsing).
# Inject a 'KeyError' bug and fire a burst of synthetic traffic
.\tools\Start-SreDemo.ps1 -Bug KeyError -LoadCount 30
Within seconds of the 500 errors appearing in Application Insights, the SRE Agent extracts the stack trace, maps the error to the specific line of code, and opens a GitHub Issue assigned to Copilot with the diagnostic payload.
Measuring Success: Incident Value Tracking
A self-healing pipeline must prove its ROI. The Azure SRE Agent includes Incident Value Tracking to quantify impact:
- Median Time to Mitigate (MTTM): The agent tracks the P50 resolution time, comparing the agent’s autonomous response against a human baseline. By focusing on the median, we get an honest look at the “Discovery-to-Fix” loop without being skewed by outlier incidents.
- Hours Saved (Toil Reduction): Every minute an agent spends running Kusto queries or parsing stack traces is a minute an engineer didn’t have to spend on manual “log spelunking.” The portal aggregates these saved engineering hours, providing a clear tally of the operational toil avoided.
- Success Rate (Remediation Efficacy): This tracks the percentage of incidents where the agent’s investigation successfully led to a mitigation. In our case, it measures the “Merge Rate” of agent-initiated Pull Requests.
Key Takeaways
- Investigate, Don’t Just Alert: The value of an SRE agent is in the rapid context gathering that usually burns engineer time.
- Context is King: The agent is only as good as its access to “Live State” (telemetry) and “Intent” (source code).
- Safety via PRs: Treat the agent as a “Senior Investigator,” but keep the human as the “Release Manager.”
The next time a service fails at 3:00 AM, don’t wake up to a vague alert. Wake up to a diagnosed root cause and a staged fix waiting for your approval.

Leave a Reply