
Azure Open Datasets have entered the preview phase, providing us with easy access to curated public datasets to accelerate our data & AI projects. This post will demonstrate how to use Azure Open Datasets with Databricks by loading a curated NOAA weather dataset.
Azure Open Datasets offers a growing number of datasets, including weather data. Be sure to visit the Azure Open Dataset catalog frequently to explore other available options: Azure Open Dataset catalog.
Setting up Databricks
If you don’t already have an Azure Databricks workspace than follow the steps below to add a Databricks resource to Azure. Otherwise, you can skip to creating a cluster.
Don’t already have an Azure account? No problem, you can create a free account here.

Creating an Azure Databricks resource is straightforward; give the workspace a name, select your subscription, resource group and location. The pricing tier is up to you. We will not be using any Premium features in this post; however, there is no harm in selecting the Premium pricing tier especially if you will want to load the data into Databricks Delta sometime in the future.

Once your resource is finished creating, typically a few minutes, you can launch the workspace.

Creating the Databricks Cluster
While creating the workspace is fun, there is not much we can do with data until we create a cluster. So next we will create a cluster.

First click on the Clusters link located on the left navigation bar.
Then click on Create Cluster on the top of the Cluster page.
Azure Open Dataset Python SDK requires python 3.6!
For your cluster to run python >=3.6 you will want to choose one of the following Databricks Runtimes:
- Runtime: 5.4 ML (does not have to be GPU) = python 3.6
- Runtime: 5.5 ML (does not have to be GPU) = python 3.6.5

Don’t forget to start your cluster.

Install Azure Open Dataset SDK
For Databricks to use Azure Open Datasets we will need to install the python SDK. The following steps will guide you through installing a python package from PyPI.
First go to the workspace landing page by clicking on Azure Databricks in the navigation bar.
Then click on Import Library

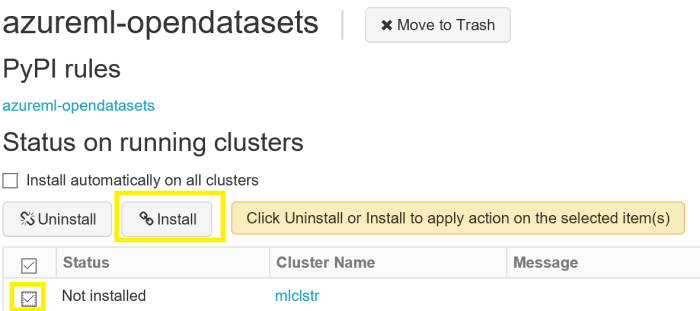
Next on the Create Library page you will select PyPI and add the package: azureml-opendatasets. Click Create.

Finally, install the library on your running cluster by checking the cluster and clicking Install. It may take a minute or two to complete the install.
Notebook to Load Data
With the cluster running and the library installed we can create our Databricks Notebook to load the NOAA data.
Again click on Azure Databricks on the left navigation bar.
Then click on New Notebook.

Create a Python Notebook using your running cluster.

Add the following code to your notebook. I included the output I received from Databricks when executing the code.
Code to load last month of weather data into a Spark Dataframe
from azureml.opendatasets import NoaaIsdWeather
from datetime import datetime
from dateutil.relativedelta import relativedelta
end_date = datetime.today()
start_date = datetime.today() - relativedelta(months=1)
#Get historical weather data in the past month.
isd = NoaaIsdWeather(start_date, end_date)
df = isd.to_spark_dataframe()
Code to print schema
df.printSchema()
Code to Display 5 Rows
display(df.limit(5))
Conclusion
Azure Open Datasets can accelerate your ML projects and I am excited to see what addition datasets get added to the catalog.
For a comparison, please check out Using Azure Notebook Workflows to Ingest NOAA Weather Data to see how NOAA weather data was loaded using NOAAs APIs and Databricks Notebook Workflows. While this is not a 100% 1-to-1 comparison, you should be able to see how Azure Open Datasets can be used to simplify loading publicly available data assets.
Please let me know your thoughts and please rate the post.
Best, Jonathan

Leave a Reply